1. OpenAI DALL·E 3来了,集成ChatGPT,生图效果太炸了
原文:https://mp.weixin.qq.com/s/P4HwP3VwzSnndD5LSt8pXw
终于,OpenAI 的文生图 AI 工具 DALL-E 系列迎来了最新版本 DALL・E 3,而上个版本 DALL・E 2 还是在去年 4 月推出的。
OpenAI 表示,「DALL・E 3 比以往系统更能理解细微差别和细节,让用户更加轻松地将自己的想法转化为非常准确的图像。」

是不是真如 OpenAI 所说的那样呢?眼见为实,我们来看以下 DALL・E 3 与 DALL・E 2 的生成效果比较,同样的 prompt「一幅描绘篮球运动员扣篮的油画,并伴以爆炸的星云」,左图 DALL・E 2 在细节、清晰度、明亮度等方面显然逊于右图 DALL・E 3。(说实话,让我想起了布洛芬....)
除了炸裂的生图效果之外,此次 DALL・E 3 的最大特点是与 ChatGPT 的集成,它原生构建在 ChatGPT 之上,用 ChatGPT 来创建、拓展和优化 prompt。这样一来,用户无需在 prompt 上花费太多时间。具体来讲,通过使用 ChatGPT,用户不必绞尽脑汁地想出详细的 prompt 来引导 DALL・E 3 了。当输入一个想法时,ChatGPT 会自动为 DALL・E 3 生成量身定制的、详细的 prompt。同时用户也可以使用自己的 prompt。至于集成 ChatGPT 后的效果怎么样?OpenAI CEO 山姆・奥特曼兴奋地展示了 DALL・E 3 的连续性生成结果,简直称得上完整的「故事片」。
ChatGPT 集成并不是 DALL・E 3 唯一的新特点,它还能生成更高质量的图像,更准确地反映提示内容。DALL・E 将文本 prompt 转换成图像。即使是 DALL・E 2 ,也会经常忽略特定的措辞导致出错。但 OpenAI 的研究人员说,最新版本能更好地理解上下文,并且处理较长的 prompt 效果会更好。此外,它还能更好地处理向来困扰图像生成模型的内容,如文本和人手。
可以看到在上图将 prompt 中的每一个细节都表现出来了。半透明的质感、画面底部的波涛汹涌、阳光与厚厚的云层、心脏中的宇宙景象,以及难倒很多图像生成模型的文字展现,DALL・E 3 都顺利地完成了这些任务。那么,DALL・E 3 能不能成为 Midjourney 「杀手」呢?推特用户 @MattGarciaEth 已经将二者生成的图片进行了很多比较。大家觉得哪个更好呢?
目前,DALL・E 3 处于研究预览版本。OpenAI 计划将 DALL・E 3 的发布时间错开, 将于 10 月份首先向 ChatGPT Plus 和 ChatGPT Enterprise 用户发布,随后在秋季向研究实验室及其 API 服务发布。不过,该公司没有透露何时或者是否计划发布免费的公开版本。
2. GPT-4终结人工标注!AI标注比人类标注效率高100倍,成本仅1/7
原文:https://mp.weixin.qq.com/s/AwXljsdH1SG0qzNeYTaprA
除了GPU,还有什么是训练一个高效的大模型必不可少且同样难以获取的资源?高质量的数据。OpenAI正是借助基于人类标注的数据,才一举从众多大模型企业中脱颖而出,让ChatGPT成为了大模型竞争中阶段性的胜利者。但同时,OpenAI也因为使用非洲廉价的人工进行数据标注,被各种媒体口诛笔伐。
而那些参与数据标注的工人们,也因为长期暴露在有毒内容中,受到了不可逆的心理创伤。
总之,对于数据标注,一定需要找到一个新的方法,才能避免大量使用人工标注带来的包括道德风险在内的其他潜在麻烦。所以,包括谷歌,Anthropic在内的AI巨头和大型独角兽,都在进行数据标注自动化的探索。

除了巨头们的尝试之外,最近,一家初创公司refuel,也上线了一个AI标注数据的开源处理工具:Autolabel。

Autolabel:用AI标注数据,效率最高提升100倍这个工具可以让有数据处理需求的用户,使用市面上主流的LLM(ChatGPT,Claude等)来对自己的数据集进行标注。refuel称,用自动化的方式标注数据,相比于人工标注,效率最高可以提高100倍,而成本只有人工成本的1/7!
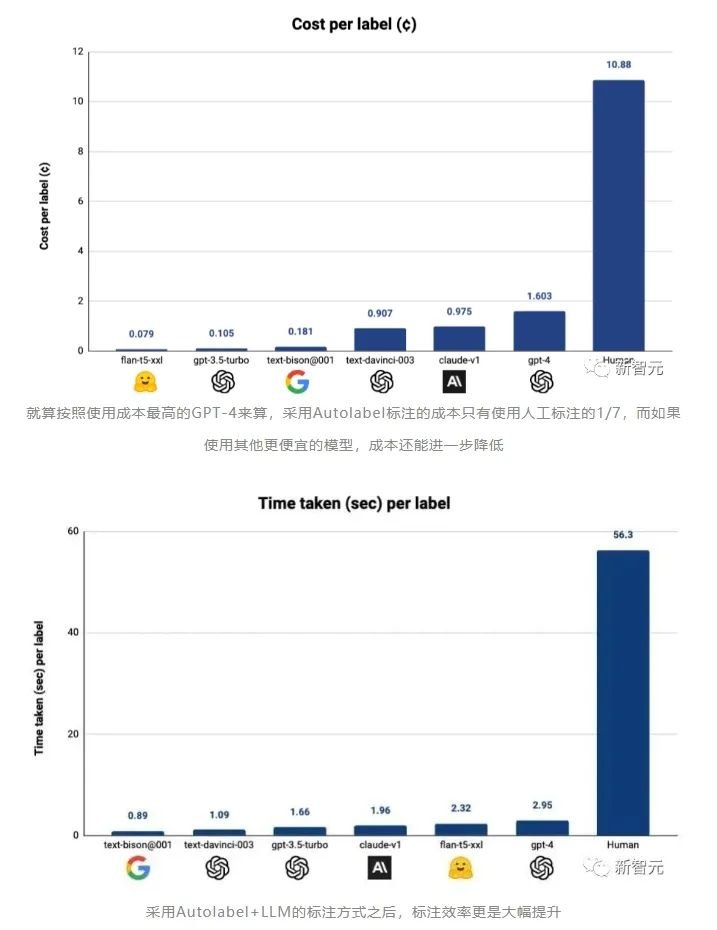
对于LLM标注质量的评估,Autolabel的开发者创立了一个基准测试,通过将不同的LLM的标注结果和基准测试中不同数据集中收纳的标准答案向比对,就能评估各个模型标注数据的质量。
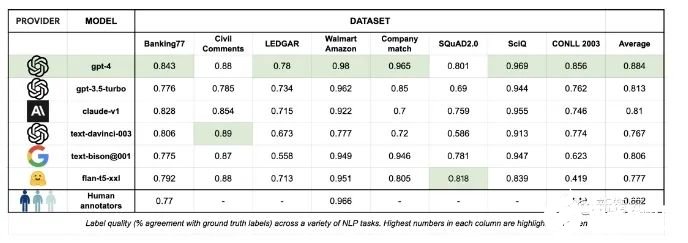
当Autolabel采用GPT-4进行标注时,获得了最高的准确率——88.4%,超过了人类标注结果的准确率86.2%。而且其他比GPT-4便宜得多的模型的标注准确率,相比GPT-4来说也不算低。开发者称,在比较简单的标注任务中采用便宜的模型,在困难的任务中采用GPT-4,将可以大大节省标注成本,同时几乎不影响标注的准确率。Autolabel支持对自然语言处理项目进行分类,命名实体识别,实体匹配和问答。支持主流的所有LLM提供商:OpenAI、Anthropic 和 Google Palm 等,并通过HuggingFace为开源和私有模型提供支持。用户可以尝试不同的提示策略,例如少样本和思维链提示。只要简单更新配置文件即可轻松估计标签置信度。Autolabel免除了编写复杂的指南,无尽地等待外部团队来提供数据支持的麻烦,用户能够在几分钟内开始标注数据。可以支持使用本地部署的私有模型在本地处理数据,所以对于数据隐私敏感度很高的用户来说,Autolabel提供了成本和门槛都很低的数据标注途径。未来更新的方向在接下来的几个月中,开发者承诺将向Autolabel添加大量新功能:支持更多LLM进行数据标注。支持更多标注任务,例如总结等。支持更多的输入数据类型和更高的LLM输出稳健性。让用户能够试验多个LLM和不同提示的工作流程。
3. Transformer+强化学习,谷歌DeepMind让大模型成为机器人感知世界的大脑
原文:https://mp.weixin.qq.com/s/pp9viv9IfdiLMFXgy4h56A
在开发机器人学习方法时,如果能整合大型多样化数据集,再组合使用强大的富有表现力的模型(如 Transformer),那么就有望开发出具备泛化能力且广泛适用的策略,从而让机器人能学会很好地处理各种不同的任务。比如说,这些策略可让机器人遵从自然语言指令,执行多阶段行为,适应各种不同环境和目标,甚至适用于不同的机器人形态。但是,近期在机器人学习领域出现的强大模型都是使用监督学习方法训练得到的。因此,所得策略的性能表现受限于人类演示者提供高质量演示数据的程度。这种限制的原因有二。-
第一,我们希望机器人系统能比人类远程操作者更加熟练,利用硬件的全部潜力来快速、流畅和可靠地完成任务。
-
第二,我们希望机器人系统能更擅长自动积累经验,而不是完全依赖高质量的演示。
从原理上看,强化学习能同时提供这两种能力。近期出现了一些颇具潜力的进步,它们表明大规模机器人强化学习能在多种应用设置中取得成功,比如机器人抓取和堆叠、学习具有人类指定奖励的异构任务、学习多任务策略、学习以目标为条件的策略、机器人导航。但是,研究表明,如果使用强化学习来训练 Transformer 等能力强大的模型,则更难大规模地有效实例化。近日,Google DeepMind 提出了 Q-Transformer,目标是将基于多样化真实世界数据集的大规模机器人学习与基于强大 Transformer 的现代策略架构结合起来。

-
论文:https://q-transformer.github.io/assets/q-transformer.pdf
-
项目:https://q-transformer.github.io/
虽然,从原理上看,直接用 Transformer 替代现有架构(ResNets 或更小的卷积神经网络)在概念上很简单,但要设计一种能有效利用这一架构的方案却非常困难。只有能使用大规模的多样化数据集时,大模型才能发挥效力 —— 小规模的范围狭窄的模型无需这样的能力,也不能从中受益。尽管之前有研究通过仿真数据来创建这样的数据集,但最有代表性的数据还是来自真实世界。因此,DeepMind 表示,这项研究关注的重点是通过离线强化学习使用 Transformer 并整合之前收集的大型数据集。离线强化学习方法是使用之前已有的数据训练,目标是根据给定数据集推导出最有效的可能策略。当然,也可以使用额外自动收集的数据来增强这个数据集,但训练过程是与数据收集过程是分开的,这能为大规模机器人应用提供一个额外的工作流程。在使用 Transformer 模型来实现强化学习方面,另一大问题是设计一个可以有效训练这种模型的强化学习系统。有效的离线强化学习方法通常是通过时间差更新来进行 Q 函数估计。由于 Transformer 建模的是离散的 token 序列,所以可以将 Q 函数估计问题转换成一个离散 token 序列建模问题,并为序列中的每个 token 设计一个合适的损失函数。最简单朴素的对动作空间离散化的方法会导致动作基数呈指数爆炸,因此 DeepMind 采用的方法是按维度离散化方案,即动作空间的每个维度都被视为强化学习的一个独立的时间步骤。离散化中不同的 bin 对应于不同的动作。这种按维度离散化的方案让我们可以使用带有一个保守的正则化器简单离散动作 Q 学习方法来处理分布转变情况。DeepMind 提出了一种专门的正则化器,其能最小化数据集中每个未被取用动作的值。研究表明:该方法既能学习范围狭窄的类似演示的数据,也能学习带有探索噪声的范围更广的数据。最后,他们还采用了一种混合更新机制,其将蒙特卡洛和 n 步返回与时间差备份(temporal difference backups)组合到了一起。结果表明这种做法能提升基于 Transformer 的离线强化学习方法在大规模机器人学习问题上的表现。总结起来,这项研究的主要贡献是 Q-Transformer,这是一种用于机器人离线强化学习的基于 Transformer 的架构,其对 Q 值使用了按维度的 token 化,并且已经可以用于大规模多样化机器人数据集,包括真实世界数据。图 1 总结了 Q-Transformer 的组件。
DeepMind 也进行了实验评估 —— 既有用于严格比较的仿真实验,也有用于实际验证的大规模真实世界实验;其中学习了大规模的基于文本的多任务策略,结果验证了 Q-Transformer 的有效性。在真实世界实验中,他们使用的数据集包含 3.8 万个成功演示和 2 万个失败的自动收集的场景,这些数据是通过 13 台机器人在 700 多个任务上收集的。Q-Transformer 的表现优于之前提出的用于大规模机器人强化学习的架构,以及之前提出的 Decision Transformer 等基于 Transformer 的模型。
4. Transformer的上下文学习能力是哪来的?
原文:https://mp.weixin.qq.com/s/7eRwSwIE-X-qfjAsOCW1WQ
为什么 transformer 性能这么好?它给众多大语言模型带来的上下文学习 (In-Context Learning) 能力是从何而来?在人工智能领域里,transformer 已成为深度学习中的主导模型,但人们对于它卓越性能的理论基础却一直研究不足。最近,来自 Google AI、苏黎世联邦理工学院、Google DeepMind 研究人员的新研究尝试为我们揭开谜底。在新研究中,他们对 transformer 进行了逆向工程,寻找到了一些优化方法。论文《Uncovering mesa-optimization algorithms in Transformers》:

论文链接:https://arxiv.org/abs/2309.05858
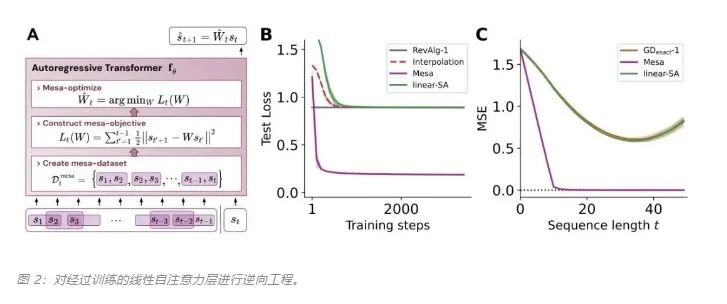
作者证明,最小化通用自回归损失会产生在 Transformer 的前向传递中运行的基于辅助梯度的优化算法。这种现象最近被称为「mesa 优化(mesa-optimization)」。此外,研究人员发现所得的 mesa 优化算法表现出上下文中的小样本学习能力,与模型规模无关。因此,新的结果对此前大语言模型中出现的小样本学习的原理进行了补充。研究人员认为:Transformers 的成功基于其在前向传递中实现 mesa 优化算法的架构偏差:(i) 定义内部学习目标,以及 (ii) 对其进行优化。
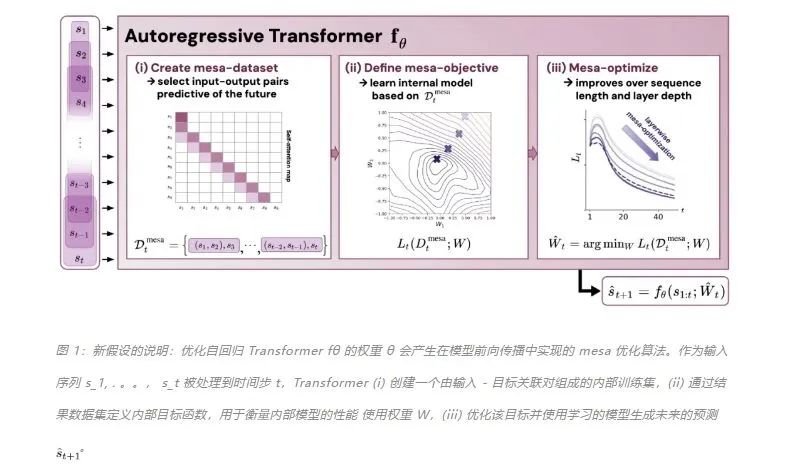
该研究的贡献包括:-
概括了 von Oswald 等人的理论,并展示了从理论上,Transformers 是如何通过使用基于梯度的方法优化内部构建的目标来自回归预测序列下一个元素的。
-
通过实验对在简单序列建模任务上训练的 Transformer 进行了逆向工程,并发现强有力的证据表明它们的前向传递实现了两步算法:(i) 早期自注意力层通过分组和复制标记构建内部训练数据集,因此隐式地构建内部训练数据集。定义内部目标函数,(ii) 更深层次优化这些目标以生成预测。
-
与 LLM 类似,实验表明简单的自回归训练模型也可以成为上下文学习者,而即时调整对于改善 LLM 的上下文学习至关重要,也可以提高特定环境中的表现。
-
受发现注意力层试图隐式优化内部目标函数的启发,作者引入了 mesa 层,这是一种新型注意力层,可以有效地解决最小二乘优化问题,而不是仅采取单个梯度步骤来实现最优。实验证明单个 mesa 层在简单的顺序任务上优于深度线性和 softmax 自注意力 Transformer,同时提供更多的可解释性。

-
在初步的语言建模实验后发现,用 mesa 层替换标准的自注意力层获得了有希望的结果,证明了该层具有强大的上下文学习能力。
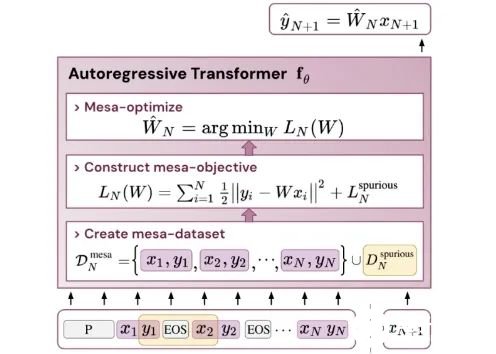
基于最近人们的工作表明,经过明确训练来解决上下文中的小样本任务的 transformer 可以实现梯度下降(GD)算法。在这里,作者展示了这些结果可以推广到自回归序列建模 —— 这是训练 LLM 的典型方法。首先分析在简单线性动力学上训练的 transformer,其中每个序列由不同的 W* 生成 - 以防止跨序列记忆。在这个简单的设置中,作者展示了 transformer 创建 mesa 数据集,然后使用预处理的 GD 优化 mesa 目标。
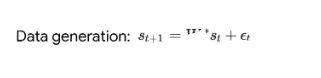
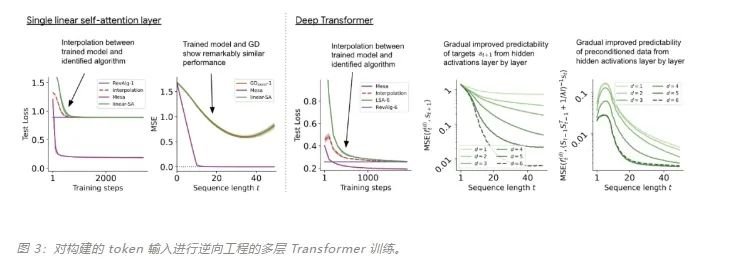
该研究在聚合相邻序列元素的 token 结构上训练深度 transformer。有趣的是,这种简单的预处理会产生极其稀疏的权重矩阵(只有不到 1% 的权重非零),从而产生逆向工程算法。
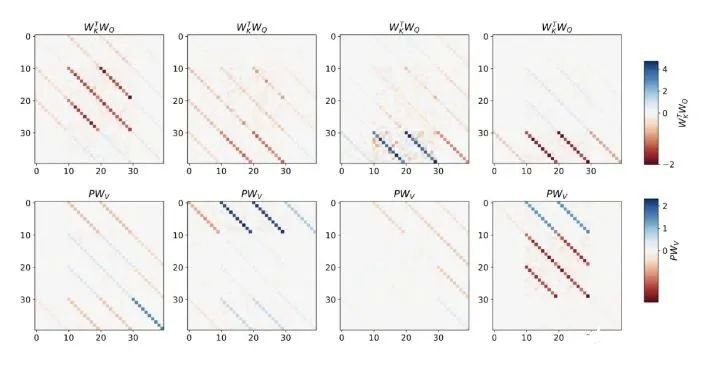
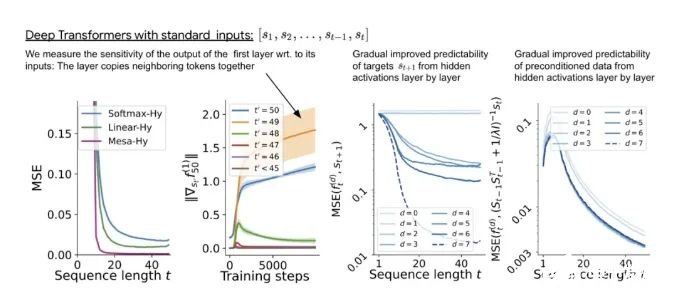
对于单层线性自注意力,权重对应一个 GD 步骤。对于深度 transformer,可解释性就变得困难。该研究依靠线性探测并检查隐藏激活是否可以预测自回归目标或预处理输入。有趣的是,两种探测方法的可预测性都会随着网络深度的增加而逐渐提高。这一发现表明模型中隐藏着预处理的 GD。
该研究发现,在构建中使用所有自由度时,可以完美地拟合训练层,不仅包括学习的学习率 η,还包括一组学习的初始权重 W_0。重要的是,如图 2 所示,学得的 one-step 算法的性能仍然远远优于单个 mesa 层。我们可以注意到,在简单的权重设置下,很容易通过基础优化发现,该层可以最优地解决此处研究的任务。该结果证明了硬编码归纳偏差有利于 mesa 优化的优势。凭借对多层案例的理论见解,先分析深度线性和 softmax 仅注意 Transformer。作者根据 4 通道结构设置输入格式,,这对应于选择 W_0 = 0。
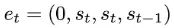
与单层模型一样,作者在训练模型的权重中看到了清晰的结构。作为第一个逆向工程分析,该研究利用这个结构并构建一个算法(RevAlg-d,其中 d 表示层数),每个层头包含 16 个参数(而不是 3200 个)。作者发现这种压缩但复杂的表达式可以描述经过训练的模型。特别是,它允许以几乎无损的方式在实际 Transformer 和 RevAlg-d 权重之间进行插值。虽然 RevAlg-d 表达式解释了具有少量自由参数的经过训练的多层 Transformer,但很难将其解释为 mesa 优化算法。因此,作者采用线性回归探测分析(Alain & Bengio,2017;Akyürek et al.,2023)来寻找假设的 mesa 优化算法的特征。在图 3 所示的深度线性自注意力 Transformer 上,我们可以看到两个探针都可以线性解码,解码性能随着序列长度和网络深度的增加而增加。因此,基础优化发现了一种混合算法,该算法在原始 mesa-objective Lt (W) 的基础上逐层下降,同时改进 mesa 优化问题的条件数。这导致 mesa-objective Lt (W) 快速下降。此外可以看到性能随着深度的增加而显着提高。因此可以认为自回归 mesa-objective Lt (W) 的快速下降是通过对更好的预处理数据进行逐步(跨层)mesa 优化来实现的。
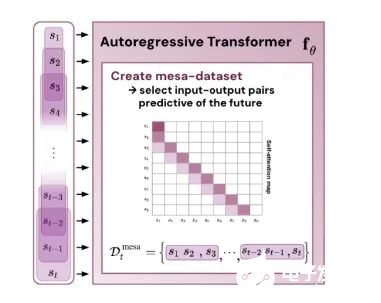
这表明,如果 transformer 在构建的 token 上进行训练,它就会通过 mesa 优化进行预测。有趣的是,当直接给出序列元素时,transformer 会自行通过对元素进行分组来构造 token,研究团队将其称为「创建 mesa 数据集」。
结论该研究表明,当在标准自回归目标下针对序列预测任务进行训练时,Transformer 模型能够开发基于梯度的推理算法。因此,在多任务、元学习设置下获得的最新结果也可以转化到传统的自监督 LLM 训练设置中。此外,该研究还发现学得的自回归推理算法可以在无需重新训练的情况下重新调整用途,以解决有监督的上下文学习任务,从而在单个统一框架内解释结果。
那么,这些与上下文学习(in-context learning)有什么关系呢?该研究认为:在自回归序列任务上训练 transformer 后,它实现了适当的 mesa 优化,因此可以进行少样本(few-shot)上下文学习,而无需任何微调。
该研究假设 LLM 也存在 mesa 优化,从而提高了其上下文学习能力。有趣的是,该研究还观察到,为 LLM 有效调整 prompt 也可以带来上下文学习能力的实质性改进。
5. 1.5T内存挑战英伟达!8枚芯片撑起3个GPT-4,华人AI芯片独角兽估值365亿
原文:https://mp.weixin.qq.com/s/GjG_OpzlAO7vGwOW7fmE-w
高端GPU持续缺货之下,一家要挑战英伟达的芯片初创公司成为行业热议焦点。8枚芯片跑大模型,就能支持5万亿参数(GPT-4的三倍) 。这是独角兽企业SambaNova刚刚发布的新型AI芯片SN40L——型号中40代表是他们第四代产品,L代表专为大模型(LLM)优化:高达1.5T的内存,支持25.6万个token的序列长度。
CEO Rodrigo Liang表示,当前行业标准做法下运行万亿参数大模型需要数百枚芯片,我们的方法使总拥有成本只有标准方法的1/25。SambaNova目前估值50亿美元(约365亿人民币),累计完成了6轮总计11亿美元的融资,投资方包括英特尔、软银、三星、GV等。他们不仅在芯片上要挑战英伟达,业务模式上也说要比英伟达走的更远:直接参与帮助企业训练私有大模型。目标客户上野心更是很大:瞄准世界上最大的2000家企业。 1.5TB内存的AI芯片最新产品SN40L,由台积电5纳米工艺制造,包含1020亿晶体管,峰值速度638TeraFLOPS。与英伟达等其他AI芯片更大的不同在于新的三层Dataflow内存系统。
1.5TB内存的AI芯片最新产品SN40L,由台积电5纳米工艺制造,包含1020亿晶体管,峰值速度638TeraFLOPS。与英伟达等其他AI芯片更大的不同在于新的三层Dataflow内存系统。-
520MB片上SRAM内存
-
65GB的高带宽HBM3内存
-
以及高达1.5TB的外部DRAM内存
与主要竞品相比,英伟达H100最高拥有80GB HBM3内存,AMD MI300拥有192GB HBM3内存。SN40L的高带宽HBM3内存实际比前两者小,更多依靠大容量DRAM。Rodrigo Liang表示,虽然DRAM速度更慢,但专用的软件编译器可以智能地分配三个内存层之间的负载,还允许编译器将8个芯片视为单个系统。
除了硬件指标,SN40L针对大模型做的优化还有同时提供密集和稀疏计算加速。他们认为大模型中许多权重设置为0,像其他数据一样去执行操作很浪费。他们找到一种软件层面的加速办法,与调度和数据传输有关,但没有透露细节,“我们还没准备好向公布是如何做到这一点的”。咨询机构Gartner的分析师Chirag Dekate认为,SN40L的一个可能优势在于多模态AI。
GPU的架构非常严格,面对图像、视频、文本等多样数据时可能不够灵活,而SambaNova可以调整硬件来满足工作负载的要求。
目前,SambaNova的芯片和系统已获得不少大型客户,包括世界排名前列的超算实验室,日本富岳、美国阿贡国家实验室、劳伦斯国家实验室,以及咨询公司埃森哲等。业务模式也比较特别,芯片不单卖,而是出售其定制技术堆栈,从芯片到服务器系统,甚至包括部署大模型。为此,他们与TogetherML联合开发了BloomChat,一个1760亿参数的多语言聊天大模型。BloomChat建立在BigScience组织的开源大模型Bloom之上,并在来自OpenChatKit、Dolly 2.0和OASST1的OIG上进行了微调。训练过程中,它使用了SambaNova独特的可重配置数据流架构,然后在SambaNova DataScale系统进行训练。
这也是这家公司最大被投资者热捧之外的最大争议点之一,很多人不看好一家公司既做芯片又做大模型。目前SambaNova包含SN40L芯片的人工智能引擎已上市,但定价没有公开。根据Rodrigo Liang的说法,8个SN40L组成的集群总共可处理5万亿参数,相当于70个700亿参数大模型。全球2000强的企业只需购买两个这样的8芯片集群,就能满足所有大模型需求。
6. 十分钟,深入浅出理解Transformer
原文:https://mp.weixin.qq.com/s/xtyP6cg6vROOXe1vlPEEew
Transformer是一个利用注意力机制来提高模型训练速度的模型。关于注意力机制可以参看这篇文章(https://zhuanlan.zhihu.com/p/52119092),trasnformer可以说是完全基于自注意力机制的一个深度学习模型,因为它适用于并行化计算,和它本身模型的复杂程度导致它在精度和性能上都要高于之前流行的RNN循环神经网络。那什么是transformer呢?你可以简单理解为它是一个黑盒子,当我们在做文本翻译任务是,我输入进去一个中文,经过这个黑盒子之后,输出来翻译过后的英文。

那么在这个黑盒子里面都有什么呢?里面主要有两部分组成:Encoder 和 Decoder
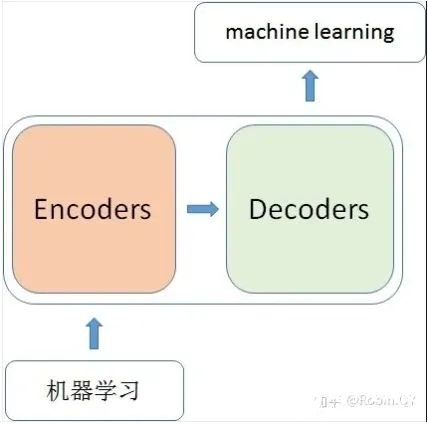
当我输入一个文本的时候,该文本数据会先经过一个叫Encoders的模块,对该文本进行编码,然后将编码后的数据再传入一个叫Decoders的模块进行解码,解码后就得到了翻译后的文本,对应的我们称Encoders为编码器,Decoders为解码器。那么编码器和解码器里边又都是些什么呢?细心的同学可能已经发现了,上图中的Decoders后边加了个s,那就代表有多个编码器了呗,没错,这个编码模块里边,有很多小的编码器,一般情况下,Encoders里边有6个小编码器,同样的,Decoders里边有6个小解码器。
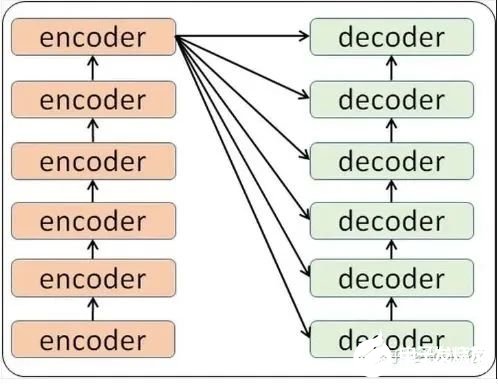
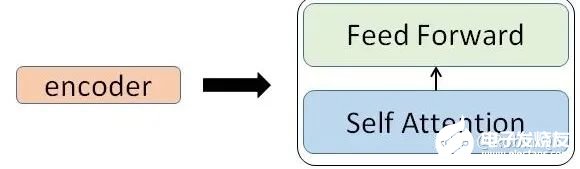
我们看到,在编码部分,每一个的小编码器的输入是前一个小编码器的输出,而每一个小解码器的输入不光是它的前一个解码器的输出,还包括了整个编码部分的输出。那么你可能又该问了,那每一个小编码器里边又是什么呢?我们放大一个encoder,发现里边的结构是一个自注意力机制加上一个前馈神经网络。
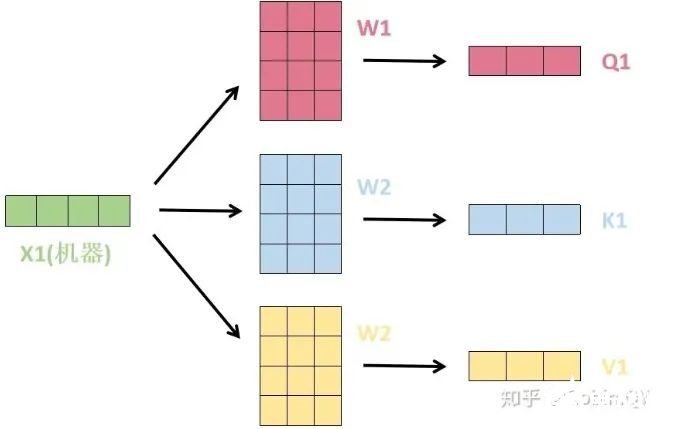
我们先来看下self-attention是什么样子的。我们通过几个步骤来解释:1、首先,self-attention的输入就是词向量,即整个模型的最初的输入是词向量的形式。那自注意力机制呢,顾名思义就是自己和自己计算一遍注意力,即对每一个输入的词向量,我们需要构建self-attention的输入。在这里,transformer首先将词向量乘上三个矩阵,得到三个新的向量,之所以乘上三个矩阵参数而不是直接用原本的词向量是因为这样增加更多的参数,提高模型效果。对于输入X1(机器),乘上三个矩阵后分别得到Q1,K1,V1,同样的,对于输入X2(学习),也乘上三个不同的矩阵得到Q2,K2,V2。
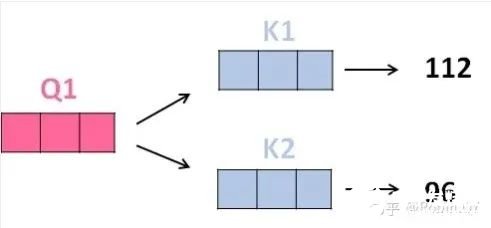
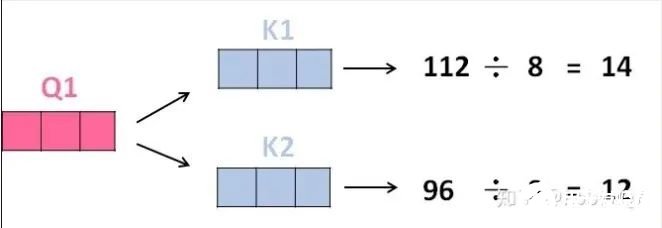
2、那接下来就要计算注意力得分了,这个得分是通过计算Q与各个单词的K向量的点积得到的。我们以X1为例,分别将Q1和K1、K2进行点积运算,假设分别得到得分112和96。
3、将得分分别除以一个特定数值8(K向量的维度的平方根,通常K向量的维度是64)这能让梯度更加稳定,则得到结果如下:
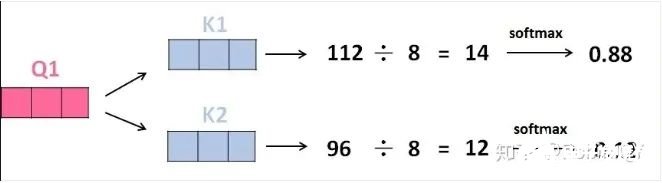
4、将上述结果进行softmax运算得到,softmax主要将分数标准化,使他们都是正数并且加起来等于1。
5、将V向量乘上softmax的结果,这个思想主要是为了保持我们想要关注的单词的值不变,而掩盖掉那些不相关的单词(例如将他们乘上很小的数字)

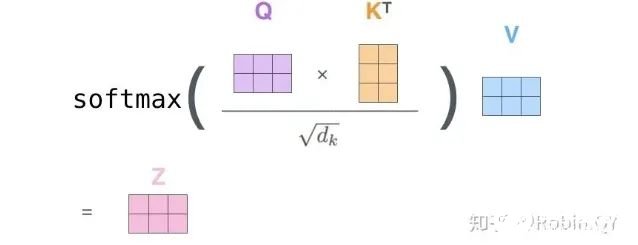
6、将带权重的各个V向量加起来,至此,产生在这个位置上(第一个单词)的self-attention层的输出,其余位置的self-attention输出也是同样的计算方式。 将上述的过程总结为一个公式就可以用下图表示:
将上述的过程总结为一个公式就可以用下图表示:
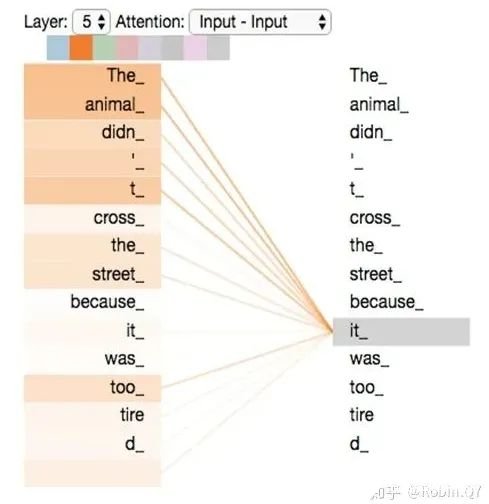
self-attention层到这里就结束了吗?还没有,论文为了进一步细化自注意力机制层,增加了“多头注意力机制”的概念,这从两个方面提高了自注意力层的性能。第一个方面,他扩展了模型关注不同位置的能力,这对翻译一下句子特别有用,因为我们想知道“it”是指代的哪个单词。
第二个方面,他给了自注意力层多个“表示子空间”。对于多头自注意力机制,我们不止有一组Q/K/V权重矩阵,而是有多组(论文中使用8组),所以每个编码器/解码器使用8个“头”(可以理解为8个互不干扰自的注意力机制运算),每一组的Q/K/V都不相同。然后,得到8个不同的权重矩阵Z,每个权重矩阵被用来将输入向量投射到不同的表示子空间。经过多头注意力机制后,就会得到多个权重矩阵Z,我们将多个Z进行拼接就得到了self-attention层的输出:

上述我们经过了self-attention层,我们得到了self-attention的输出,self-attention的输出即是前馈神经网络层的输入,然后前馈神经网络的输入只需要一个矩阵就可以了,不需要八个矩阵,所以我们需要把这8个矩阵压缩成一个,我们怎么做呢?只需要把这些矩阵拼接起来然后用一个额外的权重矩阵与之相乘即可。
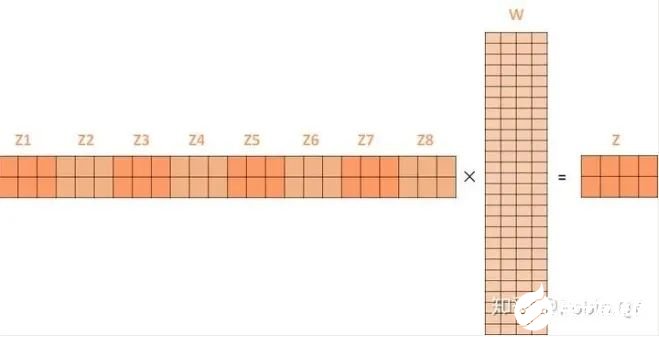
最终的Z就作为前馈神经网络的输入。接下来就进入了小编码器里边的前馈神经网模块了,关于前馈神经网络,网上已经有很多资料,在这里就不做过多讲解了,只需要知道,前馈神经网络的输入是self-attention的输出,即上图的Z,是一个矩阵,矩阵的维度是(序列长度×D词向量),之后前馈神经网络的输出也是同样的维度。以上就是一个小编码器的内部构造了,一个大的编码部分就是将这个过程重复了6次,最终得到整个编码部分的输出。然后再transformer中使用了6个encoder,为了解决梯度消失的问题,在Encoders和Decoder中都是用了残差神经网络的结构,即每一个前馈神经网络的输入不光包含上述self-attention的输出Z,还包含最原始的输入。上述说到的encoder是对输入(机器学习)进行编码,使用的是自注意力机制+前馈神经网络的结构,同样的,在decoder中使用的也是同样的结构。也是首先对输出(machine learning)计算自注意力得分,不同的地方在于,进行过自注意力机制后,将self-attention的输出再与Decoders模块的输出计算一遍注意力机制得分,之后,再进入前馈神经网络模块。
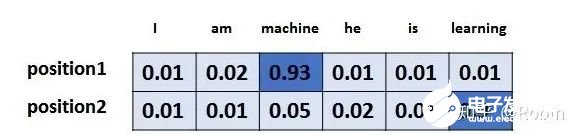
以上,就讲完了Transformer编码和解码两大模块,那么我们回归最初的问题,将“机器学习”翻译成“machine learing”,解码器输出本来是一个浮点型的向量,怎么转化成“machine learing”这两个词呢?是个工作是最后的线性层接上一个softmax,其中线性层是一个简单的全连接神经网络,它将解码器产生的向量投影到一个更高维度的向量(logits)上,假设我们模型的词汇表是10000个词,那么logits就有10000个维度,每个维度对应一个惟一的词的得分。之后的softmax层将这些分数转换为概率。选择概率最大的维度,并对应地生成与之关联的单词作为此时间步的输出就是最终的输出啦!!假设词汇表维度是6,那么输出最大概率词汇的过程如下:
以上就是Transformer的框架了,但是还有最后一个问题,我们都是到RNN中的每个输入是时序的,是又先后顺序的,但是Transformer整个框架下来并没有考虑顺序信息,这就需要提到另一个概念了:“位置编码”。Transformer中确实没有考虑顺序信息,那怎么办呢,我们可以在输入中做手脚,把输入变得有位置信息不就行了,那怎么把词向量输入变成携带位置信息的输入呢?我们可以给每个词向量加上一个有顺序特征的向量,发现sin和cos函数能够很好的表达这种特征,所以通常位置向量用以下公式来表示:
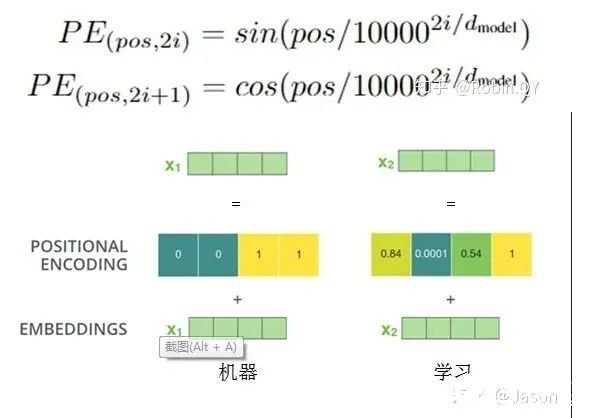
最后祭出这张经典的图,最初看这张图的时候可能难以理解,希望大家在深入理解Transformer后再看这张图能够有更深刻的认识。
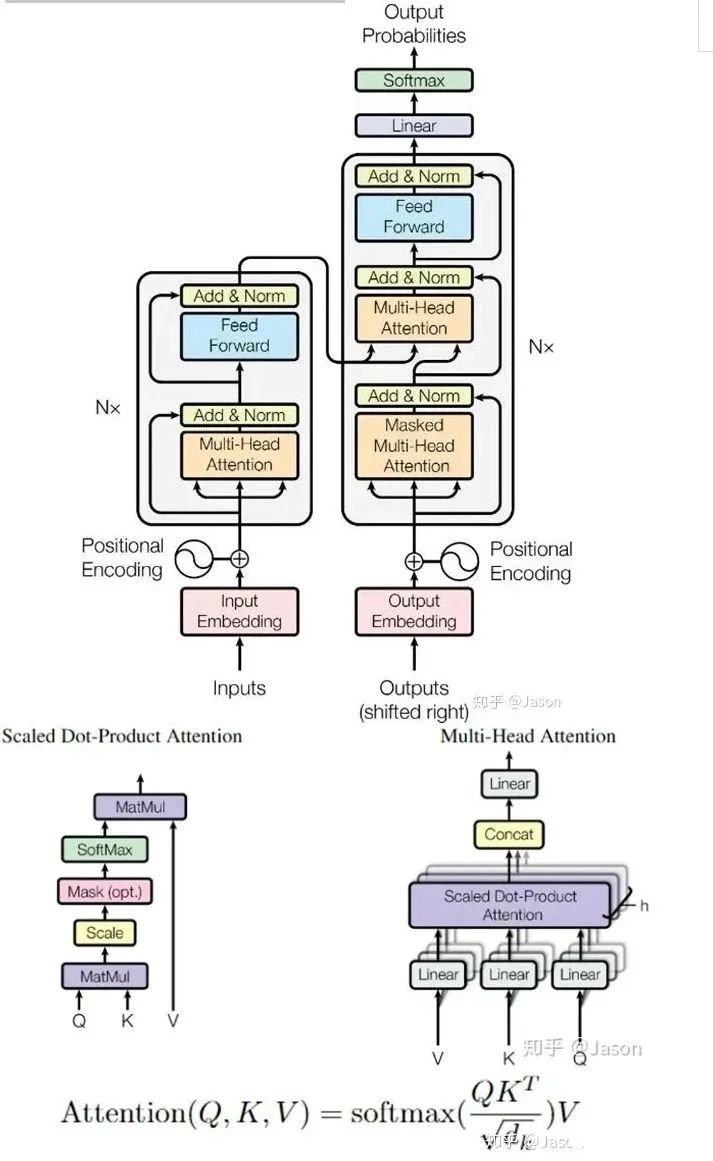
Transformer就介绍到这里了,后来的很多经典的模型比如BERT、GPT-2都是基于Transformer的思想。我们有机会再详细介绍这两个刷新很多记录的经典模型。

 【AI简报20230922期】华人AI芯片挑战英伟达,深入浅出理解Transformer
【AI简报20230922期】华人AI芯片挑战英伟达,深入浅出理解Transformer
















 工商网监
工商网监
评论