电子发烧友网报道(文/周凯扬)存内计算这个概念从被提出开始,就选定了AI作为主要应用领域,但苦于当时的需求并不算高,技术也还在完善成熟中,我们更多是在一些学术论坛和行业会议上见到存储厂商和AI芯片厂商对其高谈阔论。
可谁知道2023年我们迎来了消费级存储市场的萎靡,却又在ChatGPT的应援之下带火了高带宽内存。这不,三星、SK海力士等厂商纷纷迎来了HBM订单和单价的疯涨,也使得他们打算加速推进PIM的开发进度。
SK海力士的AiM方案
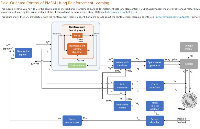
SK海力士在近期提出了他们的首个PIM方案,AiM。AiM是一个基于GDDR6的存内计算方案,专门为了加速内存负载密集的机器学习应用而设计。而GDDR6作为当下GPU产品的主要显存形式之一,提供了足够的带宽,但并没有提供额外的计算能力,更别说卸载CPU、GPU的运算任务了。

AiM存内加速器方案/ SK海力士
而在机器学习应用中,SK海力士的AiM方案可以卸载96%的计算任务,交由DRAM的存内计算单元来完成,实现了超高的内存bank并行度,显著减少了CPU与内存之间的数据移动,而且相比HBM,GDDR6明显是一个成本更低的方案。
正是因为有了这些优势,AiM可以说是专为GPT类应用打造的,SK海力士也给出了在GPT模型下的性能评估。对于GPT-2和GPT-3乃至现在的GPT-4来说,都属于内存负载密集型的应用,所以也更容易遇到内存墙的问题。
SK海力士AiM的另一大优势在于他们已经实现了全套软件栈,包括设备驱动、runtime库、框架和应用等,也支持AiM软件仿真器,支持用户自行开发AI应用,而无需硬件评估板。
三星的PIM进程
其实其他厂商也早有在PIM上布局,尤其是三星。早在2021年初推出HBM2E后,三星就已经开始规划如何充分利用这些高带宽内存的性能,其中之一就是PIM。与SK海力士不同的是,三星打造的首个PIM为HBM-PIM,在内存核心中了集成了名为可编程计算单元的AI引擎,用于处理一部分的逻辑功能。
同年的HotChips大会上,三星展示了将其HBM-PIM集成到Xilinx的AlveoAI加速器系统中。根据三星提供的数据,该方案提供了2.5倍的系统性能提升,同时将功耗降低了60%。从三星半导体的PIM技术展示也来看,他们也计划将这一技术应用到GDDR和LPDDR中,不过这几年间的主要技术公开展示都集中在HBM-PIM上。
除了这种将PIM集成到商用AI加速器的方案以外,三星也同时推出了直接将PIM集成到DRAM模块中的方案AXDIMM,通过直接在DRAM模块中对多组内存芯片进行并行运算,减少了CPU和DRAM之间的大量数据移动。
三星称在基于AI的推荐应用中,AXDIMM可以使得整体系统能效提高40%,不过对于GPT这种生成式AI类的应用能够带来多少提升我们就不得而知了,毕竟三星的PIM方案推出时大部分AI应用还停留在图片分类、文字翻译和语音识别上。
小结
从这些PIM产品的布局来看,集成式的方案或许对AI加速器厂商来说更有吸引力,不管这些计算单元是CPU、GPU、FPGA还是ASIC芯片。但无论是三星还是SK海力士,这些方案落地到产品上都需要一定的时间,所以我们可能得等到下一代产品中,才能看到存内计算的存在。
但不得不说,对于已有布局存内计算的存储厂商来说,这无疑是一大利好。过去这种和负责计算的逻辑芯片抢活干的设计无疑是自砸招牌,但现在看来却已经成了一种趋势,这类存储厂商对于市场波动的抵抗力也会更强一些。只不过目前看来这类PIM技术目前还是优先针对功耗相对较高的内存,未来要想在移动市场有所成就,还得看这些存储厂商后续会推出怎样的LPDDR-PIM方案。
相关推荐
的理念,汇聚各方的创新力量,OpenHarmony在各行各业的大规模应用已经拉开序幕,生态将迈入高速发展阶段。未来,华为期待与更多的软硬件厂商携手共进,共同推动OpenHarmony生态的繁荣和发展、技术创新与迭代,为千行百业构建坚实的数字底座。
发表于 04-19 09:17
官方提供的Ubuntu16.04(GPT)没有kernel分区,请问怎么更新kernel啊?
发表于 06-30 09:31
在RA4M2的系统重,提供了三种定时器,从手册之中可以了解:三种定时器分别是:普通PWM 32位定时器:GPT32普通PWM 16位定时器:GPT16低功耗用用异步定时器:AGT其中普通GPT比较
发表于 12-15 00:23
位压缩和“无”配置下都运行了 115 毫秒,尽管精度有所下降。我认为将 float 网络参数压缩为 uint8_t 不仅可以节省内存,还可以加快推理速度。那么,压缩模型是否应该加速推理?
发表于 01-29 06:24
,复用OS基础设施的能力,达到高效开发应用的目的。1、什么是Stage模型Stage模型提供面向对象的开发方式,规范化了进程创建的方式,提供组件化开发机制,将组件抽象为UIAbility和
发表于 03-15 10:32
进程模型的设计思路[ 问题 ]zhang_44:现在有两个状态 1,2。如果要在1 中得到一个流中断,对得到的包进行判断,如果该包是所要的,则进入状态2。若发现该包不是所要的,保持在1 不变(不能
发表于 06-14 18:05
建模分析科技进步对推动医疗电子化发展的影响本文对新技术推动下的医疗电子化领域进行了探讨,通过建立一个‘洋葱’模拟了该领域下信息流动,信息分析和采取措施的过程。该模型以科技为核心,选取了速度、存储性
发表于 11-30 11:03
本帖最后由 lerking 于 2012-7-9 21:07 编辑
【DIY进程帖】之DAC的设计与优化 大家好!这是我们参加此次赛灵思FPGA设计大赛的DIY进程贴,选的题目是基于FPGA
发表于 07-09 20:49
PIM模块的设计是什么样的工作 主要是做什么的
发表于 08-29 19:17
欧美企业高薪招聘半导体PIM工程经理与生产经理,本科以上学历,硕士优先,英语可以作为工作语言,需5年以上主管经验以及对应PIM项目经验,年薪30-40W,深圳工作,欢迎推荐及转发亲朋好友,谢谢!邮箱:hyl252770216@163.com
发表于 09-21 20:59
可能会严重影响系统性能。PIM表示"无源交调"。它代表两个或更多信号通过一个具非线性特性的无源器件传输时产生的交调产物。机械连接部分的相互作用一般会引起非线性效应,这在两种不同金属
发表于 05-10 14:43
`固纬GPT-9804/GPT9804交/直流耐压测试及绝缘及接地电阻仪联系人: 何生手 机 :15818396516(微信同号)QQ : 41026012现货销售全新固纬GPT-9804固纬电子
发表于 07-04 15:10
`何谓PIM? PIM,亦称“无源互调”(Passive Intermodulation),属于一种信号失真。由于LTE网络对PIM极其敏感,因此如何检测和降低PIM已受到越来越多的关注。 PIM由
发表于 07-13 11:20
无论如何,Fieldfox可以测试PIM(无源互调)吗?或者您正在为此开发的任何推荐的设置,选项或软件。谢谢。 以上来自于谷歌翻译 以下为原文Is there anyway a Fieldfox
发表于 11-06 10:49
由于衰减效应严重影响了通信网络的运行,因此PIM在无线通信领域越来越受关注。只要当两个频率以上的信号遇到一个非线性的电学结或类似物质,就会产生互调。其结果是产生了我们不想要的信号,这个信号的频率可以
发表于 06-11 06:31
可能会严重影响系统性能。PIM表示"无源交调",它代表两个或更多信号通过一个具非线性特性的无源器件传输时产生的交调产物。机械连接部分的相互作用一般会引起非线性效应,这在两种不同金属
发表于 06-11 09:53
应用进程预先向内核注册一个信号处理函数,然后用户进程返回,并不阻塞,当内核数据准备就绪时会发送一个信号给进程,用户进程便在信号处理函数中开始把数据拷贝到用户空间中 IO复用模型:顾名思义,即将多个进程I
发表于 10-09 16:12
8天扩容超过10万台云主机,涉及超百万核计算资源投入。庞大的数据潮构成了新基建的“基本面”,不仅推动存储、带宽进一步成为刚需,并且对存储的容量、性能等提出了更高的要求。另一方面,国产芯片产业或将迎来
发表于 04-07 11:32
基站中PIM产生的原因如何检查与解决基站中PIM
发表于 03-17 07:30
本帖翻译自IMU(加速度计和陀螺仪设备)在嵌入式应用中使用的指南。这篇文章主要介绍加速度计和陀螺仪的数学模型和基本算法,以及如何融合这两者,侧重算法、思想的讨论
发表于 08-06 08:04
一、GPT定时器 以前的延时,通过空指令进行延时,不准确。当修改时钟频率后,才用延时就会有很大的变动。而6ULL的GPT是一个高精度定时器装置。 GPT是一个32bit的向上计数器,有两个输入
发表于 12-07 12:10
EPIT定时器与GPT定时器简单介绍一、EPIT定时器1、EPIT定时器简介2、EPIT定时器寄存器二、GPT定时器1、GPT定时器简介2、GPT定时器寄存器cortex-A7拥有2个EPIT定时器
发表于 01-06 07:46
Linux NXP (I.MX6ULL) GPT高精度延时定时器0、GPT 定时器简介1、GPT 定时器特性如下:2、GPT 定时器的可选时钟源如下图所示:3、GPT 定时器结构如下图所示:3.1、GPT 定时器结构中各部分意义如下:4、GPT 定时器有两种工作
发表于 01-12 06:46
定时器 GPT2 模块这次简单介绍下GPT2GPT2 模块框图**捕捉/重载寄存器 CAPREL 可用来捕捉定时器 T5 的值, 或者重载定时器 T6。 同时, 特殊模式促进两种功能对寄存器
发表于 02-22 07:57
的问题,而对于不同地址的访问并不是缓存一致性协议所要考虑的问题。存储一致性问题在任何具有或不具有高速缓存的系统中都存在,虽然高速缓存的存在有可能进一步加剧存储一致性问题。存储器模型(memory model
发表于 04-11 15:42
小灵通PIM卡读写软件
发表于 11-22 23:20
•75次下载
pim卡资料生成器
发表于 11-22 23:23
•6次下载
针对用户对远程数据存储与异地数据备份的需求增加,提出一种基于IPv6协议的Internet存储服务模型。设计应用层的Internet存储访问协议,结合IPv6协议的安全性特点设计安全存储模型
发表于 04-13 09:13
•15次下载
本文提出了一种新的PIM-Proxy 组播通信设计方案,通过对PIM 的加入消息进行增加代理域的扩展,从而解决了基于MPLS 网络的核心路由器无法参与到组播树建立的问题。并且详细分析
发表于 08-12 08:30
•11次下载
已有的实时系统模型无法动态创建新进程.为此,基于时间自动机模型,提出了异步多进程时间自动机模型,将每个进程抽象为进程时间自动机,其部分状态能够触发新进程,考虑到队列会导致模型图灵完备,进程都被缓存
发表于 12-29 14:10
•0次下载
云存储中的数据可能会遭受非法窃取或篡改,从而使用户数据的机密性面临威胁。为了更加安全、高效地存储海量数据,提出一种攴持索引、可追溯、可验证的云存储与区块链结合的存储模型CBaS( Cloud
发表于 05-10 16:07
•7次下载
、Tensorflow占据AI框架市场主导地位,国内大厂加速布局AI框架技术; 3、AI框架技术从工具逐步走向社区,生态加速形成,未来围绕安全可信、场景落等维度呈现显著发展趋势; 二、GPT开启AI大模型时代,国内外大厂发力布局,商业化空间加速打开:
发表于 03-29 17:06
•0次下载
Hifn携业内首款硬件加速型存储解决方案亮相SNW秋季大会
存储和网络创新的推动厂商Hifn公司参加了本月14-17日在美国达拉斯Gaylord Texan酒店举行的网络存储世界(SNW)大会,并对
发表于 10-17 08:33
•522次阅读
中国电信备份(PIM)业务
备份(PIM)业务
一、产品介绍
中国电信“备份(PIM)”产品为
发表于 05-21 09:46
•6764次阅读
智原科技的USB3.0控制芯片加速进程
Faraday Solution, Your Fastrack to USB3.0!
Equipped with largest IP portfolio, experienced and r
发表于 05-22 12:54
•702次阅读
商用化进程加速,WAPI测试实验室落成
2009年11月5日,由WAPI产业联盟主办的“WAPI测试实验室落成”发布会在京召开。
WAPI产业联盟通过广泛
发表于 11-11 09:10
•575次阅读
本文详细介绍了八大存储芯片厂商排名。存储芯片是嵌入式系统芯片的概念在存储行业的具体应用,目前存储芯片在我们的生活中也已经得到普遍的运用。
![的头像]() 发表于
发表于 04-08 11:52
•10.3w次阅读
推动64位边界
![的头像]() 发表于
发表于 05-31 09:51
•655次阅读
在谈GPT 2.0之前,先回顾下它哥GPT 1.0,这个之前我在介绍Bert模型的时候介绍过,过程参考上图,简述如下:GPT 1.0采取预训练+FineTuning两个阶段,它采取
![的头像]() 发表于
发表于 02-18 08:55
•6785次阅读
在谈GPT 2.0之前,先回顾下它哥GPT 1.0,这个之前我在介绍Bert模型的时候介绍过,过程参考上图,简述如下:GPT 1.0采取预训练+FineTuning两个阶段,它采取
![的头像]() 发表于
发表于 02-18 09:56
•9070次阅读
能有这样出色的表现,不是没有原因的,GPT-2各种特定领域的语言建模任务中都取得了很好的分数。作为一个没有经过任何领域数据专门训练的模型,它的表现,比那些专为特定领域数据集(例如维基百科,新闻,书籍)上训练的模型。有图有真相:
![的头像]() 发表于
发表于 03-07 14:45
•7105次阅读
共同推动中国存储行业发展,加速存储国产化。
![的头像]() 发表于
发表于 05-15 16:58
•3211次阅读
2019将成为中国存储器发展的关键年,希望在强有力的政策支持下,加上国内厂商的不懈努力,中国存储器能在不久的将来真正引领世界。
![的头像]() 发表于
发表于 06-04 16:27
•4650次阅读
更好的性能,但是高额的存储空间、计算资源消耗是使其难以有效的应用在各硬件平台上的重要原因。所以,卷积神经网络日益增长的深度和尺寸为深度学习在移动端的部署带来了巨大的挑战,深度学习模型压缩与加速
![的头像]() 发表于
发表于 06-08 17:26
•4407次阅读

在今年的全国两会上,氢能首次被写入政府工作报告。预计这一事件将对我国正在重构的能源工业体系产生深远影响,加速推进我国氢燃料电池业的发展进程。政策的利好也引来推动各大企业争相布局,而以上市公司为代表的大企业的加入则有助进一步加速我国氢燃料电池产业化的进程。
发表于 08-17 10:51
•833次阅读
本模型的实现基于Grover模型,并修改其代码库以匹配GPT-2的语言建模训练目标。由于他们的模型是在类似的大型语料库上进行训练的,因此大部分代码和超参数都可以重复使用。本模型没有从Grover中大幅改变超参数。
![的头像]() 发表于
发表于 09-01 07:11
•2684次阅读
就在本周,OpenAI宣布,发布了7.74亿参数GPT-2语言模型,15.58亿的完整模型也有望于几个月内发布,并将GPT-2这6个月的进展情况在博客上和大家做了介绍,本文将为大家梳理。
![的头像]() 发表于
发表于 09-01 09:10
•2331次阅读
近年来,随着人工智能热潮兴起,自动驾驶汽车的发展也非常迅猛。不仅谷歌、百度等科技互联网企业相继入局,传统汽车巨头如丰田、福特、宝马等也不甘落后,自动驾驶领域的竞争愈发激烈。在这样的情况下,人们对于自动驾驶汽车越发期待,企业也加速推动其商业化进程。
发表于 03-10 14:15
•349次阅读
据IDC预测,2025年的全球数据量将达175ZB,全新的数字时代对存储提出了新的需求,要实现资源的敏捷交付、数据的永久在线和应用的加速整合。对此,存储如何应对挑战,成功实现智能化升级也成为众多企业必须考虑的重点问题。
![的头像]() 发表于
发表于 05-18 17:33
•2424次阅读
存储芯片是未来物联网、大数据、云计算等新兴领域不可或缺的关键元件,因此存储芯片的自主可控对我国新一轮信息化进程的推进具有十分重要的战略意义。中国作为全球电子产品的制造基地,长期以来都是存储器产品最大的需求市场,但是国内存储芯片的自制率较低,国产替代的空间十分广阔。
![的头像]() 发表于
发表于 06-15 17:39
•8349次阅读
OpenAI的一组研究人员最近发表了一篇论文,描述了GPT-3,这是一种具有1,750亿个参数的自然语言深度学习模型,比以前的版本GPT-2高100倍。该模型经过了将近0.5万亿个单词的预训练,并且在不进行微调的情况下,可以在多个NLP基准上达到最先进的性能。
发表于 07-08 17:36
•1951次阅读
受益于加速计算技术的不断突破,机器学习、深度学习模型训练和推理速度持续提升,加快推动了AI应用产业化的进程。从厂商情况来看,2020年GTC、英伟达发布了将算力再度提升数十倍的安培架构的A100
发表于 07-31 11:24
•481次阅读
近期,加快芯片国产化进程已经成为中国科技企业最重要的议题之一,中国存储器芯片设计与制造公司——长江存储正在加速生产。长江存储将缓慢提高其NAND芯片产量,以争取更多的市场份额。
![的头像]() 发表于
发表于 09-23 10:05
•2388次阅读
还记得前不久被捧上天的GPT-3么?那个只有被邀请的用户才能测试使用的,号称史上最大AI模型。 OpenAI的1,750亿参数语言模型GPT-3在6月份发布的时候就备受关注,当时,猿妹还和大家分享了
![的头像]() 发表于
发表于 09-25 11:38
•2181次阅读

的 OpenAI 放出了 GPT-3 这个巨型 NLP 模型怪兽,包含 1750 亿参数,比 2 月份微软刚推出的全球最大深度学习模型 Turing NLG 大上十倍,是其前身 GPT-2 参数的 100 倍
![的头像]() 发表于
发表于 03-19 14:19
•1.9w次阅读
在数字经济大环境下,各省市以及各企业也都在布局产业数字化转型,为实现经济高质量发展奠定坚实的基矗区块链作为数字经济发展的技术基础,正在走向融合,加速产业化进程。通过与人工智能、云计算、物联网、大数据等前沿技术深度融合、集成创新,推动数字产业化进程。
![的头像]() 发表于
发表于 12-01 10:27
•1827次阅读
在存储的快速发展过程中,不同的厂商对云存储提供了不同的结构模型,在这里,我们介绍一个比较有代表性的云存储结构模型。
发表于 12-25 11:23
•2535次阅读
最近,GPT-3火了!相信你已经在网上看到各种有关GPT-3的演示。这个由OpenAI创建的大型机器学习模型,它不仅可以自己写论文,还会写诗歌,就连你写的代码都能帮你写了。 下面还是先让你看看
![的头像]() 发表于
发表于 01-06 17:06
•1813次阅读
古谚道:“熟读唐诗三百首,不会作诗也会吟。” 这句话放在目前的人工智能语言模型中也非常适用。 此前,OpenAI 的研究人员开发出 “GPT-3”,这是一个由 1750 亿个参数组成的 AI
![的头像]() 发表于
发表于 01-18 17:16
•1853次阅读
虽然GPT-3没有开源,却已经有人在复刻GPT系列的模型了。 例如,慕尼黑工业大学的Connor Leahy,此前用200个小时、6000RMB,复现了GPT-2。 又例如,基于150亿参数
![的头像]() 发表于
发表于 02-13 09:24
•2230次阅读
2020年由于疫情,我们渡过了不平凡的一年,上半年全球存储市场受到了一定影响,但也加速了远程办公等企业数字化的进程,下半年中国快速恢复经济生产,成为了稳定全球存储市场大盘的关键。全球主流存储厂商也
![的头像]() 发表于
发表于 01-27 15:58
•5054次阅读
继GPT-3问世仅仅不到一年的时间,Google重磅推出Switch Transformer,直接将参数量从GPT-3的1750亿拉高到1.6万亿,并比之前最大的、由google开发的语言模型
![的头像]() 发表于
发表于 01-27 16:26
•1494次阅读

GPT3终于开源!不过,不是官方开的(别打我 Eleuther AI推出的名为GPT-Neo的开源项目,于晨4点于twitter正式宣布:已经开源了复现版GPT-3的模型参数(1.3B和2.7B级别
![的头像]() 发表于
发表于 03-31 17:46
•2270次阅读
。 据统计,大基金二期目前已经公开的投资项目已经超过10个,包括中芯国际、紫光展锐、中微公司、思特威、长川科技、艾派克电子、华润微、南大光电等企业。 近日,从工商信息中获悉,半导体存储器公司佰维存储获得了由大基金
![的头像]() 发表于
发表于 09-10 14:51
•7968次阅读
Turing-NLG相继出现。 2020年6月OpenAI在发布了GPT-3,这是当时训练的最大模型,具有1750亿个参数。近段时间,浪潮、英伟达与微软相继发布2500亿参数、5300亿参数的巨量模型,超过GPT-3。 中国工程院院士王恩东认为,人工智能的大模型时代已经到来,利用先
![的头像]() 发表于
发表于 10-18 14:41
•2654次阅读

自2018年谷歌发布BERT以来,预训练大模型经过三年的发展,以强大的算法效果,席卷了NLP为代表的各大AI榜单与测试数据集。2020年OpenAI发布的NLP大模型GPT-3,实现了千亿级数据参数
![的头像]() 发表于
发表于 10-27 08:46
•3252次阅读
NLP中,预训练大模型Finetune是一种非常常见的解决问题的范式。利用在海量文本上预训练得到的Bert、GPT等模型,在下游不同任务上分别进行finetune,得到下游任务的模型。然而,这种方式
![的头像]() 发表于
发表于 03-21 15:33
•1342次阅读
GPT-2 PyTorch 模型的替代品,可提供高达 21x CPU 的推理加速比。要为您的模型实现此加速, 从 TensorRT 8.2 开始今天的学习 .
![的头像]() 发表于
发表于 03-31 17:25
•1816次阅读

基于华为打造的人工智能融合赋能平台,智慧龙岗加速城市智能化升级的进程。
![的头像]() 发表于
发表于 04-08 10:43
•4201次阅读
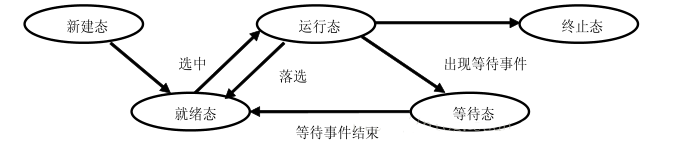
一个进程从创建而产生至撤销而消亡的整个生命周期,可以用一组状态加以刻划,根据三态模型,进程的生命周期可分为如下三种进程状态: 1. 运行态(running):占有处理器正在运行 2. 就绪态
发表于 05-10 08:56
•2720次阅读
数字技术与医疗行业的加速融合,为医疗行业注入了新动能,并不断推动医疗机构快速实现服务水平和管理能力的双提升,也让精准医疗、远程医疗、互联网诊疗等新兴医疗模式得到快速发展。而医疗终端作为连接患者、医生
![的头像]() 发表于
发表于 06-21 16:05
•1024次阅读
使用 NGC 目录中的生产级模型,加速 AI 开发工作。
![的头像]() 发表于
发表于 06-28 15:46
•536次阅读
自2018年谷歌发布BERT以来,预训练大模型经过几年的发展,以强大的算法效果,席卷了以NLP为代表的各大AI榜单与测试数据集。2020年OpenAI发布的NLP大模型GPT-3,实现了千亿级参数
![的头像]() 发表于
发表于 08-11 09:10
•1105次阅读
人类语言与蛋白质有很多共同点,至少在计算建模方面。这使得研究团队将自然语言处理(NLP)的新方法应用于蛋白质设计。其中,德国Bayreuth大学Birte Höcker的蛋白质设计实验室,描述了基于OpenAI的GPT-2的语言模型ProtGPT2,以基于自然序列的原理生成新的蛋白质序列。
![的头像]() 发表于
发表于 09-08 16:24
•716次阅读
这篇文章是大型Transformer模型(例如 EleutherAI 的 GPT-J 6B 和 Google 的 T5-3B)的优化推理指南。这两种模型在许多下游任务中都表现出良好的效果,并且是研究人员和数据科学家最常用的模型之一。
![的头像]() 发表于
发表于 10-10 15:57
•2531次阅读
通过 NVIDIA GPU 加速平台,Colossal-AI 实现了通过高效多维并行、异构内存管理、大规模优化库、自适应任务调度等方式,更高效快速部署 AI 大模型训练与推理。
![的头像]() 发表于
发表于 10-19 09:39
•714次阅读
发挥出最大威力。但其实AI对存储也很重要,AI 时刻推动着存储的发展,究其原因绕不开存内计算(PIM :Processing in-memory)。 存内计算是一项打破传统冯诺依曼架构的新型运算架构,通过将存储和计算有机结合,直接利用存储单元进行计算,极
![的头像]() 发表于
发表于 11-10 10:22
•222次阅读
Vitis Model Composer是一个基于模型的设计工具,可在MATLAB和 Simulink 环境中进行快速设计,可通过自动代码生成在FPGA上加速投产进程。
![的头像]() 发表于
发表于 11-22 10:08
•344次阅读
GPT 是 Decooding 模型的一种变体,没有 Encoder 模块,没有交叉多头注意力模块,使用 GeLU 作为激活函数。
![的头像]() 发表于
发表于 02-07 09:32
•488次阅读
在分析越狱工具shadow之前,所有越狱工具都是对进程进行注入挂钩来实现。
![的头像]() 发表于
发表于 02-23 09:21
•110次阅读
ChatGPT 是基于GPT-3.5(Generative Pre-trained Transformer 3.5)架构开发的对话AI模型,是InstructGPT 的兄弟模型。 ChatGPT很可能是OpenAI 在GPT-4 正式推出之前的演练,或用于收集大量对话数据。
发表于 02-24 10:05
•739次阅读
电子发烧友网报道(文/李弯弯)大模型,又称为预训练模型、基础模型等,大模型通常是在大规模无标注数据上进行训练,学习出一种特征和规则。近期火爆的ChatGPT,便是基于GPT大模型的一个自然语言处理
![的头像]() 发表于
发表于 02-26 00:44
•2811次阅读
ChatGPT 是在 GPT-3.5 系列模型的基础上微调而来的,我们看到很多研究也在紧随其后紧追慢赶,但是,与 ChatGPT 相比,他们的新研究效果到底有多好?
发表于 02-27 11:44
•119次阅读
AI的另一个重要推动者是大型预训练模型的出现,这些模型已经开始广泛应用于自然语言和图像处理,以在迁移学习的帮助下处理各种各样的应用。
发表于 03-02 11:23
•3731次阅读
在预训练阶段,GPT 选择 transformer 的 decoder 部分作为模型的主要模块,transformer 是 2017年 google 提出的一种特征抽取模型,GPT 以多层 transformer 堆叠的方式构成了整个预训练模型结构。
![的头像]() 发表于
发表于 03-03 11:14
•973次阅读
PIM一体成型微电感已处于业内领先优势,适应 5G时代市场需求.我们有完整的PIM一体成型电感 全套解决方案,不受材料限制,不受技术限制, 不受设备限制. 冷压成型是PIM超微一体成型电感的第一个
发表于 03-04 10:19
•33次阅读

ChatGPT 是 OpenAI 发布的最新语言模型,比其前身 GPT-3 有显著提升。与许多大型语言模型类似,ChatGPT 能以不同样式、不同目的生成文本,并且在准确度、叙述细节和上下文连贯性上具有更优的表现。
发表于 03-10 09:41
•215次阅读
电子发烧友网报道(文/吴子鹏)北京时间3月15日凌晨,人工智能研究公司OpenAI正式发布了其下一代大型语言模型GPT-4。目前,ChatGPT的Plus订阅用户已经可以使用GPT-4,其他用户需要
![的头像]() 发表于
发表于 03-16 01:58
•2462次阅读

ChatGPT升级 史上最强大模型GPT-4发布 OpenAI正式推出了ChatGPT升级版本,号称史上最强大模型GPT-4发布。OpenAI期待GPT-4成为一个更有价值的AI工具。 GPT
![的头像]() 发表于
发表于 03-15 18:15
•1449次阅读
而且 GPT-4 是多模态的,同时支持文本和图像输入功能。此外,GPT-4 比以前的版本“更大”,这意味着其已经在更多的数据上进行了训练,并且在模型文件中有更多的权重,这也使得它的运行成本更高。
![的头像]() 发表于
发表于 03-17 10:31
•1231次阅读
北京时间3月15日凌晨,OpenAI发布了ChatGPT的最新“升级版本”——GPT4模型,OpenAI在官网表示,GPT4是一个能接受图像和文本输入,并输出文本的多模态模型,是OpenAI在扩展
![的头像]() 发表于
发表于 03-22 22:26
•783次阅读
GPT-4 相比 GPT-3.5 具有四方面的能力提升:1) GPT-4 具有一定的多模态能力,能够进行图文结合输入的分析。
发表于 03-30 14:36
•232次阅读
人工智能是第四次技术革命中的重要技术。近期ChatGPT不断出圈,OpenAI随即又推出了新一代大语言模型GPT-4,再次引发了全球对人工智能技术发展的关注。微软宣布正式把GPT-4模型装进
![的头像]() 发表于
发表于 04-04 14:38
•602次阅读
GPT4可以搞电机吗?
![的头像]() 发表于
发表于 04-06 10:08
•675次阅读
正所谓「大力出奇迹」,把参数量调「大」能提高模型性能已经成为了大家的普遍共识。但是仅仅增加模型参数就够了吗?仔细阅读GPT的一系列论文后就会发现,仅仅增加模型参数是不够的。它们的成功在很大程度上还归功于用于训练它们的大量和高质量的数据。
![的头像]() 发表于
发表于 04-06 10:54
•262次阅读
无论是 “一触即通” 还是 “一通百通”,都意味着视觉模型已经 “理解” 了图像结构。SAM 精细标注能力与 SegGPT 的通用分割标注能力相结合,能把任意图像从像素阵列解析为视觉结构单元,像生物视觉那样理解任意场景,通用视觉 GPT 曙光乍现。
![的头像]() 发表于
发表于 04-09 09:40
•664次阅读
SK海力士在近期提出了他们的首个PIM方案,AiM。AiM是一个基于GDDR6的存内计算方案,专门为了加速内存负载密集的机器学习应用而设计。而GDDR6作为当下GPU产品的主要显存形式之一,提供了足够的带宽,但并没有提供额外的计算能力,更别说卸载CPU、GPU的运算任务了。
![的头像]() 发表于
发表于 04-10 10:56
•160次阅读

 GPT模型推动存储厂商加速PIM进程
GPT模型推动存储厂商加速PIM进程 0
0
















 工商网监
工商网监
评论