
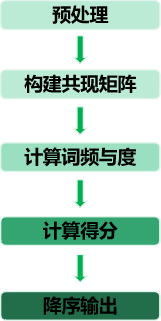
 RAKE算法原理介绍
RAKE算法原理介绍
RAKE简介
RAKE英文全称为Rapid Automatic keyword extraction,中文称为快速自动关键字提取,是一种非常高效的关键字提取算法,可对单个文档进行操作,以实现对动态集合的应用,也可非常轻松地应用于新域,并且在处理多种类型的文档时也非常有效。
2
算法思想
RAKE算法用来做关键词(keyword)的提取,实际上提取的是关键的短语(phrase),并且倾向于较长的短语,在英文中,关键词通常包括多个单词,但很少包含标点符号和停用词,例如and,the,of等,以及其他不包含语义信息的单词。
RAKE算法首先使用标点符号(如半角的句号、问号、感叹号、逗号等)将一篇文档分成若干分句,然后对于每一个分句,使用停用词作为分隔符将分句分为若干短语,这些短语作为最终提取出的关键词的候选词。
最后,每个短语可以再通过空格分为若干个单词,可以通过给每个单词赋予一个得分,通过累加得到每个短语的得分。一个关键点在于将这个短语中每个单词的共现关系考虑进去。最终定义的公式是:
3
算法步骤
(1)算法首先对句子进行分词,分词后去除停用词,根据停 用词划分短语;
(2)之后计算每一个词在短语的共现词数,并构建 词共现矩阵;
(3)共现矩阵的每一列的值即为该词的度deg(是一个网络中的概念,每与一个单词共现在一个短语中,度就加1,考虑该单词本身),每个词在文本中出现的次数即为频率freq;
(4)得分score为度deg与频率 freq的商,score越大则该词更重 ;
(5)最后按照得分的大小值降序 输出该词所在的短语。
下面我们以一个中文例子具体解释RAKE算法原理,例如“系统有声音,但系统托盘的音量小喇叭图标不见了”,经过分词、去除停用词处理 后得到的词集W = {系统,声音,托盘,音量,小喇叭,图标,不见},短语集D={系统,声音,系统托盘,音量小喇叭图标不见},词共现矩阵如表: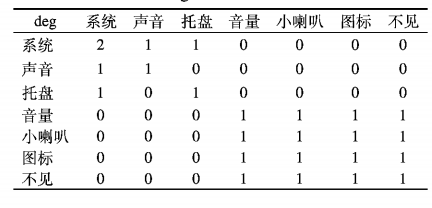
每一个词的度为deg={"系统”:2,“声音”:1,“托盘”:1; “音量” :3; “小喇叭” :3,“图标” :3,“不见” :3},频率freq = { “系统” :2, “声音” :1, “托盘” :1 ;“音量” :1;“小喇叭” :1, “图标”丄“不见” :1}, score ={“系统”:1,“声音”:1,“托 盘” :1 ;“音量” :1小喇叭” :3, “图标” :3, “不见” :3 },输出结果为{音量小喇叭图标不见 ,系统托盘,系统,声音}
4
代码实现
importstring fromtypingimportDict,List,Set,Tuple PUNCTUATION=string.punctuation.replace(''','')#Donotuseapostropheasadelimiter ENGLISH_WORDS_STOPLIST:List[str]=[ '(',')','and','of','the','amongst','with','from','after','its','it','at','is', 'this',',','.','be','in','that','an','other','than','also','are','may','suggests', 'all','where','most','against','more','have','been','several','as','before', 'although','yet','likely','rather','over','a','for','can','these','considered', 'used','types','given','precedes', ] defsplit_to_tokens(text:str)->List[str]: ''' Splittextstringtotokens. Behaviorissimilartostr.split(), butemptylinesareomittedandpunctuationmarksareseparatedfromword. Example: split_to_tokens('Johnsaid'Hey!'(andsomeotherwords.)')-> ->['John','said',''','Hey','!',''','(','and','some','other','words','.',')'] ''' result=[] foritemintext.split(): whileitem[0]inPUNCTUATION: result.append(item[0]) item=item[1:] foriinrange(len(item)): ifitem[-i-1]notinPUNCTUATION: break ifi==0: result.append(item) else: result.append(item[:-i]) result.extend(item[-i:]) return[itemforiteminresultifitem] defsplit_tokens_to_phrases(tokens:List[str],stoplist:List[str]=None)->List[str]: """ Mergetokensintophrases,delimitedbyitemsfromstoplist. Phraseisasequenceoftokenthathasthefollowingproperties: -phrasecontains1ormoretokens -tokensfromphrasegoinarow -phrasedoesnotcontaindelimitersfromstoplist -eithertheprevious(notinaphrase)tokenbelongstostoplistoritisthebeginningoftokenslist -eitherthenext(notinaphrase)tokenbelongstostoplistoritistheendoftokenslist Example: split_tokens_to_phrases( tokens=['Mary','and','John',',','some','words','(','and','other','words',')'], stoplist=['and',',','.','(',')'])-> ->['Mary','John','somewords','otherwords'] """ ifstoplistisNone: stoplist=ENGLISH_WORDS_STOPLIST stoplist+=list(PUNCTUATION) current_phrase:List[str]=[] all_phrases:List[str]=[] stoplist_set:Set[str]={stopword.lower()forstopwordinstoplist} fortokenintokens: iftoken.lower()instoplist_set: ifcurrent_phrase: all_phrases.append(''.join(current_phrase)) current_phrase=[] else: current_phrase.append(token) ifcurrent_phrase: all_phrases.append(''.join(current_phrase)) returnall_phrases defget_cooccurrence_graph(phrases:List[str])->Dict[str,Dict[str,int]]: """ Getgraphthatstorescooccurenceoftokensinphrases. Matrixisstoredasdict, wherekeyistoken,valueisdict(keyissecondtoken,valueisnumberofcooccurrence). Example: get_occurrence_graph(['Mary','John','somewords','otherwords'])->{ 'mary':{'mary':1}, 'john':{'john':1}, 'some':{'some':1,'words':1}, 'words':{'some':1,'words':2,'other':1}, 'other':{'other':1,'words':1} } """ graph:Dict[str,Dict[str,int]]={} forphraseinphrases: forfirst_tokeninphrase.lower().split(): forsecond_tokeninphrase.lower().split(): iffirst_tokennotingraph: graph[first_token]={} graph[first_token][second_token]=graph[first_token].get(second_token,0)+1 returngraph defget_degrees(cooccurrence_graph:Dict[str,Dict[str,int]])->Dict[str,int]: """ Getdegreesforalltokensbycooccurrencegraph. Resultisstoredasdict, wherekeyistoken,valueisdegree(sumoflengthsofphrasesthatcontainthetoken). Example: get_degrees( { 'mary':{'mary':1}, 'john':{'john':1}, 'some':{'some':1,'words':1}, 'words':{'some':1,'words':2,'other':1}, 'other':{'other':1,'words':1} } )->{'mary':1,'john':1,'some':2,'words':4,'other':2} """ return{token:sum(cooccurrence_graph[token].values())fortokenincooccurrence_graph} defget_frequencies(cooccurrence_graph:Dict[str,Dict[str,int]])->Dict[str,int]: """ Getfrequenciesforalltokensbycooccurrencegraph. Resultisstoredasdict, wherekeyistoken,valueisfrequency(numberoftimesthetokenoccurs). Example: get_frequencies( { 'mary':{'mary':1}, 'john':{'john':1}, 'some':{'some':1,'words':1}, 'words':{'some':1,'words':2,'other':1}, 'other':{'other':1,'words':1} } )->{'mary':1,'john':1,'some':1,'words':2,'other':1} """ return{token:cooccurrence_graph[token][token]fortokenincooccurrence_graph} defget_ranked_phrases(phrases:List[str],*, degrees:Dict[str,int], frequencies:Dict[str,int])->List[Tuple[str,float]]: """ GetRAKEmeasureforeveryphrase. Resultisstoredaslistoftuples,everytuplecontainsofphraseanditsRAKEmeasure. Itemsaresortednon-ascendingbyRAKEmeasure,thanalphabeticallybyphrase. """ processed_phrases:Set[str]=set() ranked_phrases:List[Tuple[str,float]]=[] forphraseinphrases: lowered_phrase=phrase.lower() iflowered_phraseinprocessed_phrases: continue score:float=sum(degrees[token]/frequencies[token]fortokeninlowered_phrase.split()) ranked_phrases.append((lowered_phrase,round(score,2))) processed_phrases.add(lowered_phrase) #Sortbyscorethanbyphrasealphabetically. ranked_phrases.sort(key=lambdaitem:(-item[1],item[0])) returnranked_phrases defrake_text(text:str)->List[Tuple[str,float]]: """ GetRAKEmeasureforeveryphraseintextstring. Resultisstoredaslistoftuples,everytuplecontainsofphraseanditsRAKEmeasure. Itemsaresortednon-ascendingbyRAKEmeasure,thanalphabeticallybyphrase. """ tokens:List[str]=split_to_tokens(text) phrases:List[str]=split_tokens_to_phrases(tokens) cooccurrence:Dict[str,Dict[str,int]]=get_cooccurrence_graph(phrases) degrees:Dict[str,int]=get_degrees(cooccurrence) frequencies:Dict[str,int]=get_frequencies(cooccurrence) ranked_result:List[Tuple[str,float]]=get_ranked_phrases(phrases,degrees=degrees,frequencies=frequencies) returnranked_result
执行效果:
if__name__=='__main__': text='Mercy-classincludesUSNSMercyandUSNSComforthospitalships.Credit:USNavyphotoMassCommunicationSpecialist1stClassJasonPastrick.TheUSNavalAirWarfareCenterAircraftDivision(NAWCAD)LakehurstinNewJerseyisusinganadditivemanufacturingprocesstomakefaceshields.........' ranked_result=rake_text(text) print(ranked_result)
关键短语抽取效果如下:
[
('additivemanufacturingprocesstomakefaceshields.the3dprintingfaceshields',100.4),
('usnavyphotomasscommunicationspecialist1stclassjasonpastrick',98.33),
('usnavy’smercy-classhospitalshipusnscomfort.currentlystationed',53.33),
...
]
-
算法
+关注
关注
23文章
4209浏览量
90034 -
网络
+关注
关注
14文章
7004浏览量
86841 -
Rake
+关注
关注
0文章
2浏览量
7282
发布评论请先 登录
相关推荐
SVPWM算法架构介绍
基于模拟退火结合粒子群算法介绍
自适应RAKE接收技术
RAKE接收机与分集接收
扩频通信系统中Rake接收性能仿真研究

RAKE接收机的原理介绍和使用MATLAB以及RAKE接收机的性能说明等介绍















 工商网监
工商网监
评论